Understanding Sharding as a Pattern
I first encountered the term sharding during my master's degree while using NetKet for Variational Monte Carlo (VMC) simulations. The name itself gave me an idea that it probably involved partitioning something, and while I knew it helped code run across multiple GPUs, I never dug deeper than that.
Recently, the term kept reappearing in discussions about LLMs (like here), so I finally decided to investigate. I started with a simple Google search on "sharding", and was surprised to find that nearly every result focused on databases. This made me ponder for a bit: I first heard about sharding through VMC calculations, decided to look it up because of LLMs, yet ended up reading about databases.
This isn't unusual in computer science. Many concepts tie together different domains through an underlying pattern (iterators are an example that comes to mind here). Similarly, for sharding, there is also a core idea (partitioning data or computation in a specific way), which shows up in databases and distributed machine learning, each adapting the pattern to solve their specific scaling challenges.
Database Sharding
Let's start with database sharding, since that's where I encountered the term first in my search. In software architecture, the most common place you'll see sharding defined explicitly is databases. The etymology is very obscure, to be honest. Wikipedia traces it to a 1988 paper called "SHARD" (A System for Highly Available Replicated Data), but despite being referenced in many academic papers, extensive searches by librarians, academics, and archivists have never found it. Even the original authors (Sarin, DeWitt, and Rosenberg) don't have copies. One author confirmed it was an internal company memo that likely never got proper distribution.
Interestingly, the authors later clarified their "SHARD" concept was about partitioning the network for high availability, not horizontal data partitioning as "sharding" is understood today. The modern database term may actually come from Ultima Online (1997), where the game's multiple server instances were called "shards" after the game's lore: a magical realm trapped in a crystal and shattered into pieces, each shard containing a refracted copy of the original world.
In the context of databases, systems like MongoDB and Cassandra use sharding when storage or I/O demands exceed what a single server can handle. Sharding is about partitioning the dataset and replication is about copying it for availability. In practice, production systems often do both: split into shards, then replicate each shard.

The diagram above shows this clearly: an original table with five rows gets split into two shards. DB1 holds rows 1–3, DB2 holds rows 4–5. Notice that each shard keeps the same columns (ID, First Name, Last Name, Favorite Food) and only the rows are divided. This is what makes it horizontal.
Sharding in LLMs
I then looked at how modern Deep Learning uses the term. For Large Language Models, instead of the bottleneck being disk storage, it is active VRAM (Video RAM).
A 70-billion parameter model is about 140 GB of weights at FP16/BF16 (about 2 bytes per parameter; roughly 130 GiB). Even an NVIDIA A100 80GB can't hold that in VRAM. Training needs more memory on top of that for gradients and optimizer state. Unlike a database, a neural network cannot easily run from disk; the weights must be in VRAM to perform the matrix multiplications.
This is where frameworks like PyTorch implement FSDP (Fully Sharded Data Parallel). FSDP reduces memory by sharding parameters, gradients, and optimizer state across data-parallel workers. During the forward or backward pass, when computation reaches a layer, the workers briefly all-gather the full parameters for that layer, perform the computation, then discard the gathered copies. This way, no single GPU has to hold the entire model's states all the time.

The diagram above illustrates this: each GPU holds only a shard of the model state, but when computation happens, the necessary parameters are gathered temporarily, used, and then released. This all-gather/compute/discard cycle repeats for each layer during forward and backward passes.
In the JAX/Flax ecosystem, the comparable idea is explicit sharding / GSPMD-style partitioning, where you annotate how arrays (including parameters) are laid out across devices. In any case, the goal is is still to pool the high-speed memory of multiple devices to fit a model that is otherwise too big to run.
What NetKet Was Actually Doing
With this understanding, I looked back at what NetKet was actually doing in the VMC simulations.
The Neural Quantum States I used were typically small dense networks or even Restricted Boltzmann Machines. They fit easily into the memory of a single GPU, so the same complex memory-saving sharding used by PyTorch or TensorFlow was unnecessary. NetKet uses sharding to solve a different problem: time and statistical variance.
In Variational Monte Carlo, accuracy depends on the number of samples. You need hundreds of thousands of samples from the probability distribution to estimate the energy gradient correctly. Generating these samples sequentially is slow (really slow).
NetKet addresses this using JAX's SPMD (Single Program, Multiple Data) model: the model parameters are replicated on each device, while the sample batch is sharded across devices/ranks. Concretely, this means you can request (say) 80,000 MCMC samples, and NetKet will split them across 8 GPUs so each GPU generates ~10,000 samples locally—then the results are combined with a global reduction when needed.
You can see this directly from NetKet's multi-process sharding example:
# Variational state
vs = nk.vqs.MCState(sa, ma, n_samples=1008, n_discard_per_chain=10)
# Run the optimization
gs.run(n_iter=50, out=log, timeit=True)
# Sharding will shard the samples... the n_chains are split among different ranks
print(default_string, "Samples shape: ", vs.samples.shape, flush=True)
print(default_string, "Samples sharding:", vs.samples.sharding, flush=True)
print(
default_string,
"Samples is_fully_addressable: ",
vs.samples.is_fully_addressable,
flush=True,
)
The “then aggregate” part is equally important: once data is sharded, certain computations (like a sum/mean over the full sample set) require cross-process communication—effectively an MPI-style all-reduce. The same example demonstrates this idea by computing a quantity that depends on all samples, after making the array replicated so it can be accessed everywhere.
# To get the data from all samples on all ranks, replicate it
samples_replicated = jax.lax.with_sharding_constraint(
vs.samples,
shardings=jax.sharding.NamedSharding(jax.sharding.get_abstract_mesh(), P()),
)
print(
default_string,
"A quantity computed on a single rank, depending on all data: ",
np.array(samples_replicated).sum(),
flush=True,
)
In other words, NetKet's sharding here isn't about fitting a large model into memory. It's about scaling the expensive part of VMC sampling by distributing chains and samples across devices, and only paying the synchronization cost when it's time to combine results at the end of a step.
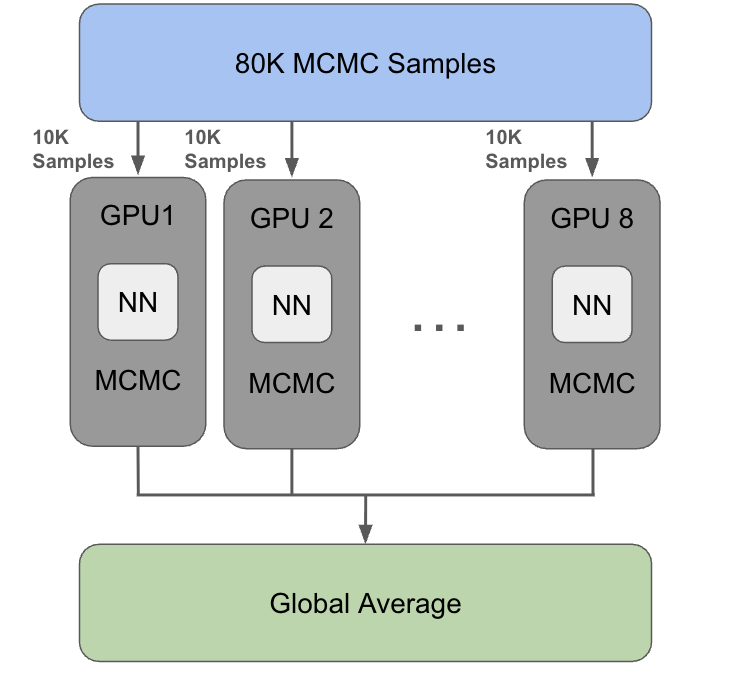
The diagram above shows this: 80K samples split into 10K chunks per GPU, each running the neural network and MCMC independently, then combining via a global average at the end. Each GPU runs the Markov chain Monte Carlo (MCMC) on its local shard of data, allowing for near-linear scaling in the sampling-heavy parts of the step.
The Unifying Pattern
After reviewing all three cases, I understood why people use the same word for these different tasks, even though the terminology doesn't map perfectly across domains. I know it might sound obvious, but I wanted to better understand why.
In databases, sharding is usually presented as horizontal partitioning (row-wise) across separate servers. You split the data by instance rather than by structure so every server holds the same columns, but different rows.
In ML/JAX/PyTorch, "sharding" generalizes to partitioning arrays or tensors across devices. This can be along the batch dimension (data parallelism), model states (FSDP-style), or other tensor axes entirely. The "horizontal vs vertical" framing from databases doesn't quite apply here.
What ties them together is that you have more work (or data) than fits on one unit, so you split it across many units and coordinate the results.
It always follows a three-step cycle:
- Split: You take the resource that is too large for one unit and partition it into independent pieces across devices or servers.
- Process: You perform the work (storage, matrix multiplication, or sampling) on all pieces simultaneously.
- Aggregate: You bring the results back together to form a cohesive whole (a query result, a gradient update, or an energy estimate).
Ok but...
Many sources still use horizontal partitioning and sharding interchangeably. In practice, engineers often use "partitioning" to mean splits within one database instance, and "sharding" to emphasize that the partitions live on separate servers, instances, or devices.
This distinction applies to all three domains we discussed:
- Databases: Splitting a table into partitions within one DB instance is partitioning, while distributing partitions across separate server instances is called sharding.
- LLMs: Slicing model state is partitioning, while placing those slices across devices is sharding (device placement/layout).
- VMC: Splitting the sample workload is partitioning, while running those partitions across devices is (data-)sharding / data parallelism.
In database literature, blogs and so on, you'll see both conventions: some sources note that people use horizontal sharding and horizontal partitioning interchangeably in practice (see Hazelcast), while others make a clearer distinction, using sharding (often described as “horizontal partitioning”) for splits distributed across separate servers/instances, and using partitioning for splits within a single server/instance (see PlanetScale). Because of that, when someone asks “should we partition or shard?”, they often mean “keep it on a single instance vs distribute across multiple instances” (see Wikipedia and this practitioner discussion).
What started as a quick Google search turned into a small rabbit hole across databases, ML frameworks, and my own thesis code. It was mostly semantics anyway, but I enjoyed the investigation.